Day 2 of Becoming an AI Developer: How LLMs Actually Work
From tokens to transformers — understand what really happens when ChatGPT replies to you, in simple, developer-friendly language.

You’ve probably used ChatGPT and thought:
“How does this thing know exactly what I’m trying to say?”
Or maybe this happened:
You asked an AI tool to generate code. It gave a perfect solution. Then one tiny change in the prompt completely broke the answer.
Confusing, right?
Most developers assume LLMs are some kind of magic. Others think they’re just giant databases copying answers from the internet.
Reality?
LLMs are surprisingly logical once you understand the building blocks.
And the good news is:
You do not need scary math to understand them.
In this article, we’ll break down:
- What tokens actually are
- Why embeddings matter
- How attention works
- What transformers really do
- How an LLM generates a response step-by-step
- A mini project to visualise token prediction
By the end, terms like tokenisation and transformers will stop sounding intimidating.
First, Let’s Kill a Common Myth
Many developers think:
“LLMs understand language like humans.”
Not exactly.
LLMs are prediction engines.
They don’t “know” things in the human sense.
They predict:
What is the next most likely token?
That’s it.
Sounds too simple?
Surprisingly, this simple idea becomes incredibly powerful at scale.
Example
Input: React is a JavaScript ____
The model predicts possible next tokens:
- library (92%)
- framework (6%)
- tool (2%)
It chooses the most probable option.
Then repeats the process.
That’s how entire paragraphs are generated.
Tiny prediction → repeated billions of times → intelligent-looking output.
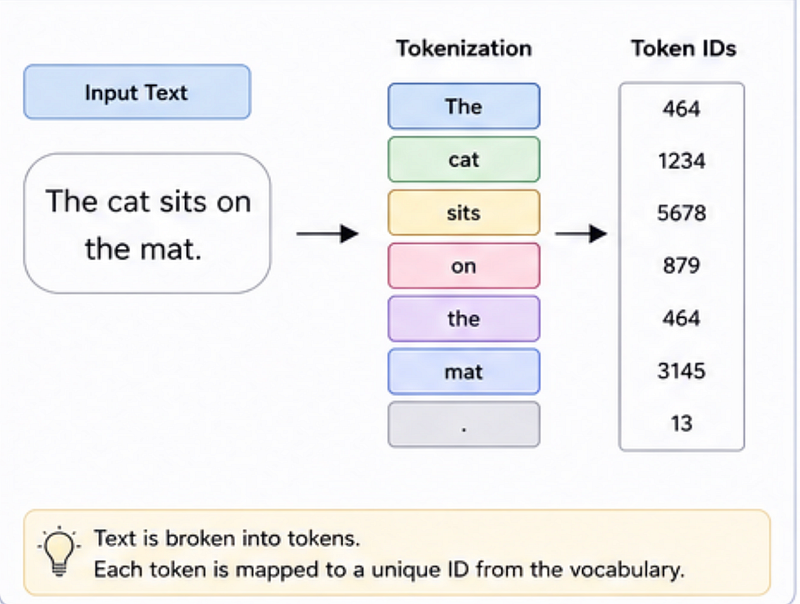
Step 1: What Are Tokens?
Before an LLM understands your text, it breaks everything into tokens.
A token is a small piece of text.
Not always a word.
Sometimes:
- a word
- part of a word
- punctuation
- spaces
- symbols
Example Tokenization
Sentence: I love JavaScript
Possible tokens: [‘I’, ‘ love’, ‘ Java’, ‘Script’]
Notice something weird?
“JavaScript” got split.
Why?
Because tokenisation helps models process text more efficiently.
Common words stay intact. Rare words get broken into smaller reusable chunks.
Why Developers Should Care
Bad prompting often happens because developers ignore token behaviour.
For example:
Huge prompts = more tokens.
More tokens means:
- higher cost
- slower responses
- reduced context window
Quick JavaScript Example
You can estimate token usage using tokeniser libraries.
import { encoding_for_model } from 'tiktoken';
const encoder = encoding_for_model('gpt-4o');
const tokens = encoder.encode(
'Explain React hooks in simple words'
);
console.log(tokens.length);Common Mistake
Many beginners think:
“1000 words = 1000 tokens”
Nope.
Usually: 100 words ≈ , 130–150 tokens depending on language and formatting.
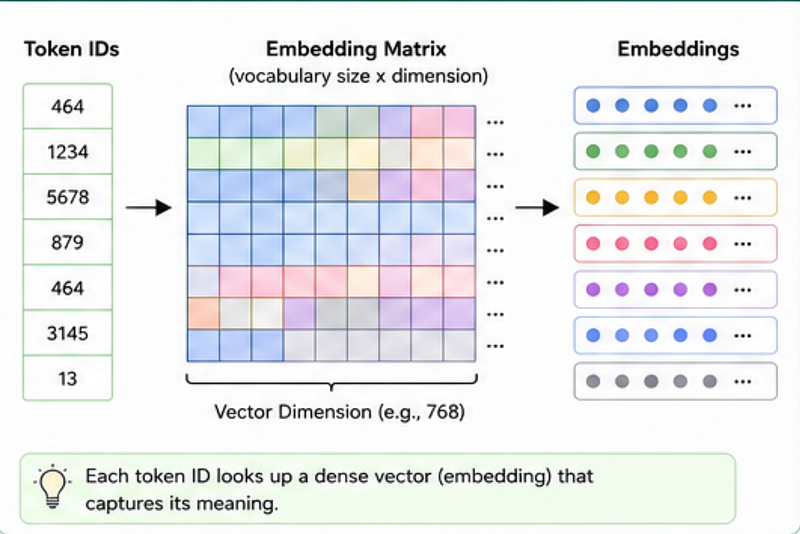
Step 2: Embeddings — How AI Understands Meaning
Now comes the interesting part.
If AI only sees tokens, how does it understand meaning?
Answer: Embeddings.
Think of embeddings as converting words into numbers that represent meaning.
Words with similar meanings end up closer together.
Example:
- Dog → close to puppy
- King → close to queen
- JavaScript → close to React
The AI doesn’t understand English like humans.
Instead, it understands relationships between vectors.
Simple Analogy
Imagine placing words on a giant map.
Related concepts stay nearby.
That’s essentially what embeddings do.

Practical Developer Use Case
Embeddings power:
- semantic search
- recommendation systems
- AI chat with documents
- RAG applications
- vector databases
For example:
Instead of keyword search: Find docs for authentication
An embedding system can also match:
- login system
- user auth
- JWT implementation
- Even if the exact words don’t match.
That’s powerful.
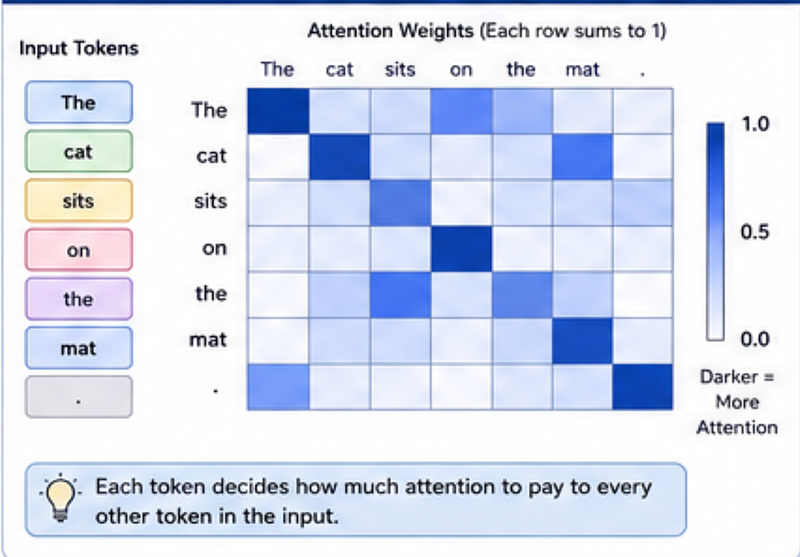
Step 3: Attention — The Real Secret Sauce
Here’s where things get interesting.
Imagine this sentence:
The bug in React was fixed because it had a memory issue.
Question:
What does “it” refer to?
- bug?
- React?
- Memory issue?
Humans naturally understand context.
LLMs do this using something called:
Attention
Attention helps the model decide:
Which words matter most right now?
Instead of treating every token equally, the model focuses on relevant ones.
Simplified Example
Sentence: The developer deployed the app after testing it.
The model gives more attention to: it → app
Not: it → developer
Why Attention Matters
Without attention:
AI responses would lose context quickly.
With attention:
LLMs maintain better meaning across long conversations.
Step 4: Transformers — The Architecture That Changed AI
A transformer is the engine that helps an LLM understand context and predict the next token intelligently.
The transformer’s job is to answer:
“Given everything written so far, what matters most, and what should come next?”
What a Transformer Does Internally
A transformer mainly performs 3 jobs:
1. Understand Context Using Attention
It checks relationships between words.
Example:
The JavaScript app crashed because it had a memory leak.Transformer asks:
What does “it” refer to?
- JavaScript?
- app?
- memory leak?
Using attention, it figures out:
it → appThis is why LLMs can maintain context.
2. Learn Patterns
Transformers learn language patterns from huge datasets.
Example patterns:
console.log(Usually followed by:
'value'Or:
React useEffect(Often followed by:
() => {}It learns probabilities and coding patterns at scale.
3. Predict the Next Best Token
After understanding context:
Input:
Node.js is used for backend _____Transformer predicts:
development (91%)
applications (6%)
servers (3%)Then repeats this process again and again.
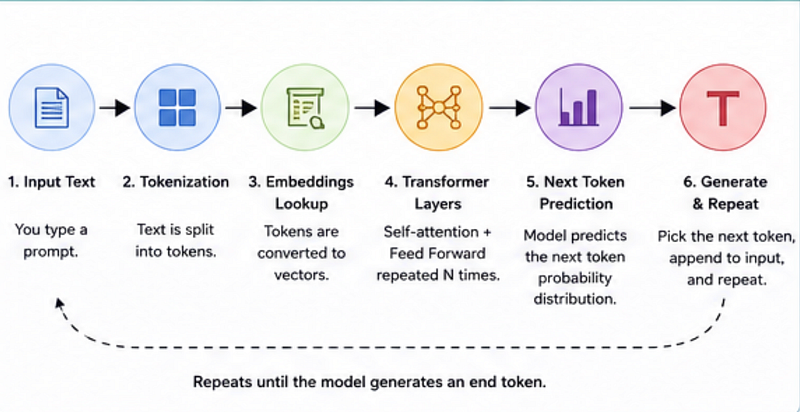
Simplified Transformer Workflow
Input Prompt
↓
Tokenizer
↓
Embeddings
↓
Transformer
(Find Context +
Understand Relationships +
Predict Patterns)
↓
Next Token Prediction
↓
Repeat Until Response CompleteBefore transformers, models struggled with long context.
Transformers solved this using:
- tokenization
- embeddings
- attention
All working together.
This architecture powers modern models like:
- ChatGPT
- Claude
- Gemini
- Llama
The key breakthrough?
Parallel processing.
Instead of reading text one word at a time, transformers process relationships much faster.
Mini Project: Build a Tiny Next-Word Predictor
Let’s simulate how prediction works.
const predictions = {
'I love': ['JavaScript', 'React', 'coding'],
'React is': ['awesome', 'popular', 'fast'],
};
function predictNext(input) {
return predictions[input] || ['I am not sure'];
}
console.log(predictNext('I love'));What This Teaches You
This is obviously not a real LLM.
But it helps you understand the core idea:
Predict the next likely token based on context.
Real LLMs just do this at a massive scale.
Billions of parameters. Millions of relationships. Huge datasets.
Same principle.
The Surprising Payoff
Here’s the counterintuitive truth:
LLMs don’t actually “think” the way most developers imagine.
Yet they still produce impressive results.
Why?
Because language itself is highly predictable.
Patterns + context + probability = intelligence-like behaviour.
This also explains:
Why hallucinations happen.
Sometimes the model predicts something that sounds statistically right — even if it’s factually wrong.
That’s why developers should treat AI as:
An extremely smart assistant, not an unquestionable source of truth.
And honestly?
That mindset alone will make you better at using AI than most developers.
Key Takeaways
If you remember only five things from this article, remember these:
- LLMs predict tokens, not thoughts
- Tokens are pieces of text, not always words
- Embeddings help AI understand meaning relationships
- Attention helps models focus on important context
- Transformers combine everything into powerful prediction systems
Your Next Step
The next time you use ChatGPT, pause and think:
“What token is the model probably predicting next?”
You’ll start seeing AI differently.
And once you understand the fundamentals, prompt engineering suddenly makes much more sense.
Missed Day 1?
Read here: AI vs ML vs Deep Learning vs GenAI
Upcoming
Day 3: How ChatGPT Actually Generates Responses
🚀 Transitioning into AI as a developer?
I’m building a practical 30-day roadmap to help developers move into AI — step by step, without random tutorials or confusion.
👉 Follow this series so you don’t miss the next day.
👉 Bookmark this article — you’ll want to revisit it.
👉 What’s the biggest thing confusing you about AI right now? Drop it in the comments — I may cover it next.